
Today a coworker remarked to me that he had been using the JavaScript native array method .filter, but found that writing a custom for loop to do the filtering was much faster. “How can this be?” we wondered, “Native is always faster!”
Since I’m skeptical by nature, my first move was to confirm my coworker’s claim in a controlled environment.
I created an array of a few million random numbers, and a function to filter then based on even or odd.
var vals = [];
for (var i = 0; i < 5000000; i++) {
vals.push(Math.floor((Math.random() * 100) + 1));
}
var f = function(x) { return x % 2 === 0; };
Then I applied a performance measurement:
function measure(f) {
var start = performance.now();
f();
var end = performance.now();
var diff = end - start
document.write(f + " took " + diff + " ms.<br />");
}
I also wrote a completely naive for-loop based filter method which I attached to the Array prototype.
Array.prototype.naiveForFilter = function(f) {
'use strict';
var results = [];
var len = this.length;
for (var i = 0; i < len; i++) {
if (f(this[i])) {
results.push(this[i]);
}
}
return results;
};
Finally, I compared the execution time of the two:
measure(function() { vals.filter(f) });
measure(function() { vals.naiveForFilter(f) });
The outcome (in Chrome) was shocking: the naive hand-rolled for loop ran in 1/5 the time of the native filter method. This seemed opposed to all possible common-sense. I asked my coworker if he had done any search, and he said there was an article from 2011, but he figured since it was so many years ago, it wouldn't still apply.
The article claims the slow-down is due to the additional safeties offered by the native method:
- It ignores deleted values and gaps in the array
- It optionally sets the execution context of the predicate function
- It prevents the predicate function from mutating the data
This still seems a little suspect, given that the native method was 5x slower. It also raises the question (just a curiosity) of how much impact each of those safeties costs. Is there one in particular that incurs a higher cost? To dig further, I pulled the Mozilla polyfill reference implementation for filter.
Adding this entry to my profiling, I found it about five times slower than the native method. Wow! So native, doing the same thing, is definitely faster. But still, the question is: where is the expense? I identified two possible cost centers visually in the polyfill: membership checking in the array using "in" and binding the context of the filter function using "call":
if (i in this) {
if (f.call(thisArg, val, i, this)) {
I guessed that the context binding was the slow part. But to find out, I made multiple versions of the filter function, beginning the naive implementation (known to be very fast), and incrementally adding checks until it approached the complexity of the reference polyfill (known to be very slow). I tested all implementations on both browsers on my machine (Chrome and IE 11). I also compared to an implementation using ES6 foreach.
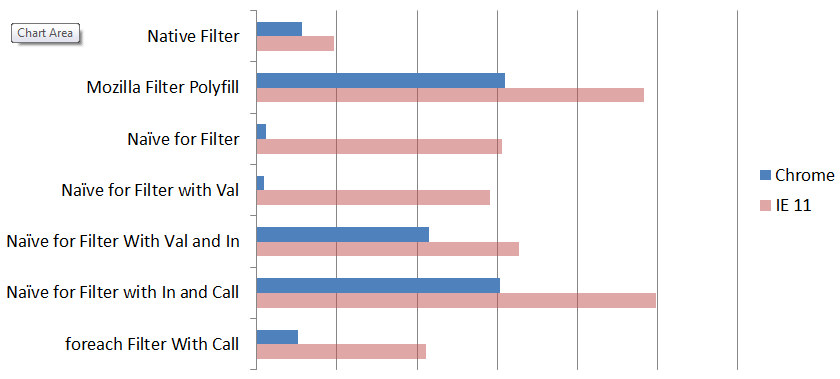
The performance differences are by far most significant in Chrome, where the use of "in" to validate if an element is present in the array is an extremely expensive operation. Introducing this check consumes the vast majority of time in the implementation. Note: this is not the same as an element being undefined, which is much cheaper check.
Interestingly, in IE 11 the performance is much more normalized, and it appears that the function binding (.call) is the most expensive incremental addition to the function, with the in being fairly cheap. IE 11 is also exposed as having poor JavaScript optimization capability, as even a tight naive JS loop is much much slower than a more involved native implementation, whereas in Chrome the opposite is true. I'm assuming Edge is much more performant but haven't tested.
So, even today, if performance is critical, it might be faster to hand roll a custom-tailored function as opposed to using the built-in natives, as the built-in natives may have special support (like filter does for sparse arrays) that are known to be not needed in your specific case. But as Knuth says, "premature optimization is the root of all evil", so always default to using the native functions unless you're sure you need something different.